Why RAG Beats Fine-Tuning for Most Enterprise Use Cases
Many organizations turn to fine-tuning as the first step when customizing AI models for their specific needs. Fine-tuning adjusts a pre-trained model by retraining it on specialized data to improve performance on particular tasks. While this can be effective, it also comes with high costs, complexity, and delays that often make it less practical.
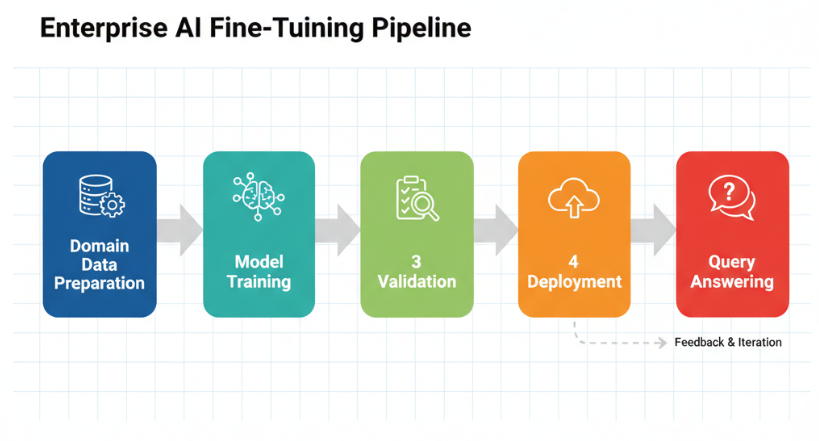
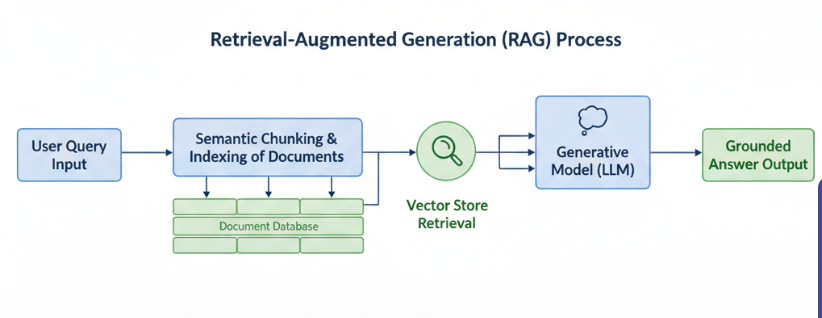
Retrieval-Augmented Generation (RAG) offers a more efficient alternative for most enterprise use cases. Instead of retraining the model, RAG systems retrieve relevant information from a knowledge base during query time and generate responses grounded in that data. This difference brings several important advantages.
First, RAG eliminates the need for expensive training cycles. Fine-tuning requires substantial computational resources, including access to GPUs, and involves time-consuming training and validation processes. With RAG, there is no retraining. Updating the data simply means refreshing the vector store or document index, which can be done continuously and quickly. This approach keeps the information current without the overhead of retraining.
Keeping data up to date is critical for business applications. Business rules, product details, and regulations often change and AI systems must reflect these changes promptly. Fine-tuning demands retraining the model every time knowledge changes, which slows down the update process. RAG separates knowledge storage from the model, allowing enterprises to add or modify documents in the retrieval system immediately.
Another significant benefit is the reduction of hallucinations. Generative models sometimes produce plausible-sounding but incorrect answers when relying solely on learned knowledge. RAG reduces this risk by grounding responses in retrieved documents. This leads to more accurate, trustworthy answers, which is essential for enterprise environments where errors can have serious consequences.
RAG systems also enable faster deployment. Fine-tuning can take weeks or longer due to dataset preparation, training, and testing. RAG architectures can be deployed in days since the generative model remains fixed and only the retrieval index changes. This speed allows businesses to respond quickly to new requirements or data.
Fine-tuning still has its place when a specific tone, style, or format is needed for outputs. However, for most tasks focused on knowledge retrieval and question answering, RAG provides a more flexible and cost-effective solution.
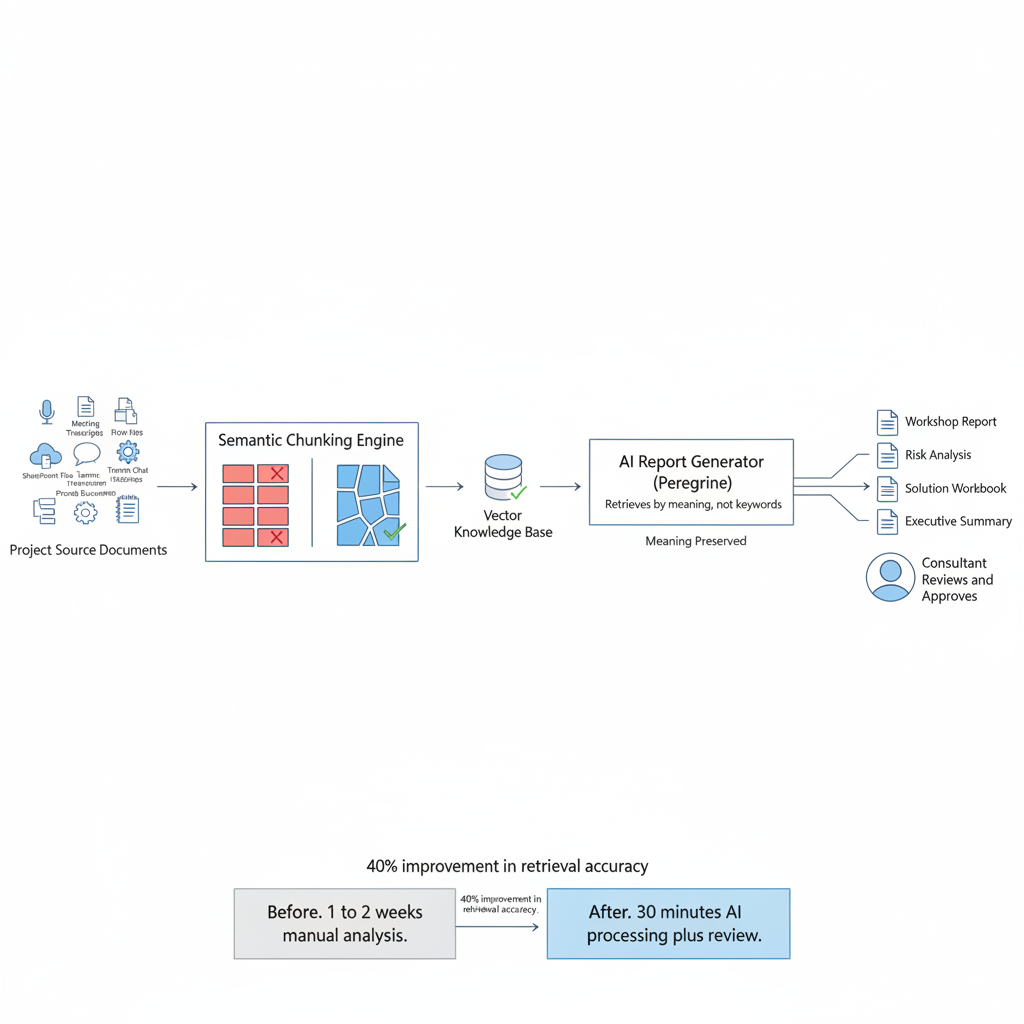
A practical example comes from Open Source Integrators, which implemented a RAG-powered system to improve requirement gathering. By using semantic chunking—breaking documents into meaningful segments rather than arbitrary splits—they increased retrieval accuracy by 40%. This improvement reduced the time needed for requirement gathering from two weeks to just thirty minutes.
The Problem. Requirements Gathering Is the Bottleneck
In a typical ERP implementation project, a consultant spends one to two weeks manually reading through hundreds of pages of documentation. Meeting transcripts, SharePoint files, Teams chat histories, existing process documents, and project notes. They highlight key decisions, extract requirements, note risks, and piece together a coherent picture of what the client needs. This work is slow, error-prone, and entirely dependent on the individual consultant's thoroughness. If they miss a requirement buried on page 47 of a transcript, that gap may not surface until months later during implementation, when fixing it costs ten times more.
How It Works. Semantic Chunking and Intelligent Retrieval
Peregrine replaces this manual process with an AI-powered pipeline that reads every document the same way a senior consultant would, but in minutes instead of weeks.
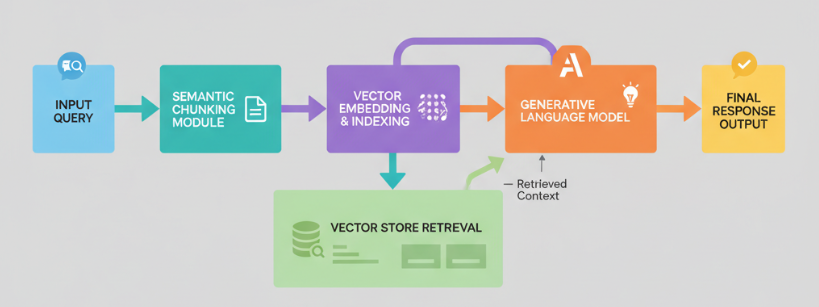
The key technical innovation is semantic chunking. Traditional document search systems split files into fixed-size blocks, say every 500 words. The problem is that a fixed split might cut a sentence about a critical compliance requirement in half, or separate a business rule from the context that explains why it exists. The system retrieves a fragment that looks relevant but is missing the information that makes it useful.
Semantic chunking works differently. The system analyzes the natural structure of each document, including paragraphs, topic shifts, and logical sections, and breaks it into segments that preserve complete ideas. A paragraph describing a three-step approval workflow stays together as one chunk. A discussion about inventory valuation rules stays paired with the exception cases that follow it. When the AI later searches for "approval process" or "inventory management," it retrieves a self-contained, meaningful answer rather than a sentence fragment.
What the Consultant Sees
From the consultant's perspective, the process is straightforward.
1. They point Peregrine at a project. All the associated documents, transcripts, and chat histories are already connected through the platform. 2. The system automatically ingests every source, breaks them into semantically meaningful segments, and indexes them for retrieval. 3. When generating a report, the AI pulls the most relevant information across all sources, not by keyword matching, but by understanding the meaning of what was discussed. 4. The output is a structured consulting deliverable, whether a workshop report, risk analysis, solution workbook, or executive summary, grounded in the actual source material, with every claim traceable to specific evidence.
The consultant reviews, refines, and approves. They are not starting from a blank page. They are editing an AI-drafted document that already contains the substance of weeks of manual analysis.
The Business Impact
This approach produced a measurable 40% improvement in retrieval accuracy, meaning the AI finds the right information from the right documents 40% more often than a traditional keyword-based system would. In practice, this means fewer missed requirements, fewer gaps in the final deliverable, and fewer costly surprises during implementation.
The time impact is equally significant. A requirement-gathering process that previously consumed one to two weeks of a senior consultant's time, reading documents, attending review sessions, writing summaries, and cross-referencing across sources, now produces a comparable output in roughly thirty minutes of compute time plus a review session. The consultant's role shifts from data extraction to quality assurance. They verify what the AI found, add judgment the AI cannot, and ensure nothing critical was misinterpreted.
For a services firm, this translates directly to margin improvement. The same consultant can support more projects. Deliverable quality becomes more consistent because it depends less on individual diligence. And the risk of scope gaps, the single most common source of budget overruns in ERP implementations, drops measurably because the system reads every page of every document, every time.
This example underscores the importance of how data is prepared for retrieval. Semantic chunking groups information by meaning and context, making it easier for the system to find relevant information compared to simple token-based splits. Enterprises can gain significant efficiency by combining effective data preparation with RAG technology.
Retrieval-Augmented Generation offers an effective, efficient approach for enterprises seeking AI solutions tailored to their domains. It balances accuracy, freshness, cost, and speed by separating knowledge storage from model generation. While fine-tuning remains useful for specialized stylistic needs, RAG should be the standard starting point for most knowledge-driven applications